


Very simply, a graph database is a database designed to treat the relationships between data as equally important to the data itself. It is intended to hold data without constricting it to a pre-defined model. Instead, the data is stored like we first draw it out - showing how each individual entity connects with or is related to others.
We live in a connected world! There are no isolated pieces of information, but rich, connected domains all around us. Only a database that natively embraces relationships is able to store, process, and query connections efficiently. While other databases compute relationships at query time through expensive JOIN operations, a graph database stores connections alongside the data in the model.
Accessing nodes and relationships in a native graph database is an efficient, constant-time operation and allows you to quickly traverse millions of connections per second per core.
Independent of the total size of your dataset, graph databases excel at managing highly-connected data and complex queries. With only a pattern and a set of starting points, graph databases explore the neighboring data around those initial starting points — collecting and aggregating information from millions of nodes and relationships — and leaving any data outside the search perimeter untouched.
As with most technologies, there are few different approaches to what makes up the key components of a graph database. One such approach is the property graph model, where data is organized as nodes, relationships, and properties (data stored on the nodes or relationships).
We will cover this model in more detail in the Data Modeling section of these guides, but for now, we will briefly define the components that make up the property graph model.
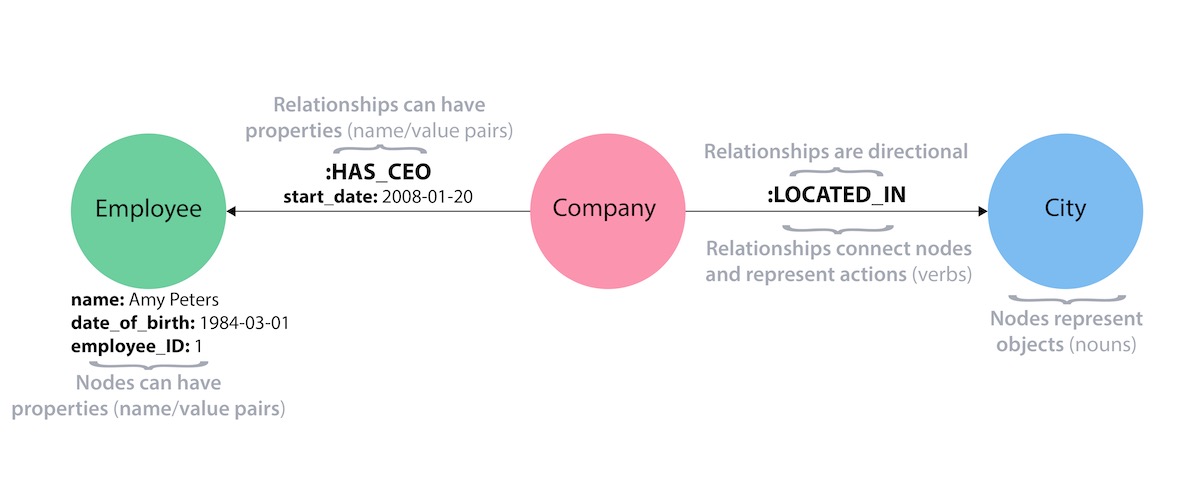
Nodes are the entities in the graph. They can hold any number of attributes (key-value pairs) called properties. Nodes can be tagged with labels, representing their different roles in your domain. Node labels may also serve to attach metadata (such as index or constraint information) to certain nodes.
Relationships provide directed, named, semantically-relevant connections between two node entities (e.g. Employee WORKS_FOR Company). A relationship always has a direction, a type, a start node, and an end node. Like nodes, relationships can also have properties. In most cases, relationships have quantitative properties, such as weights, costs, distances, ratings, time intervals, or strengths. Due to the efficient way relationships are stored, two nodes can share any number or type of relationships without sacrificing performance. Although they are stored in a specific direction, relationships can always be navigated efficiently in either direction.
Building blocks of the property graph model (click to zoom)











With gaining attention on metaverse technology, many businesses are marching towards metaverse development. The market is hungry for individuals with

From the very small classes, we are learning about the Classification of Elements and Periodicity in Properties. When you are learning about the rules

83 followers

Why use blockchain in mobile apps? Blockchain technology offers several advantages when utilized in mobile apps. Firstly, it enhances security by

The Metaverse has captivated the imagination of tech enthusiasts, entrepreneurs, and industry executives alike, offering a digital realm where people

In your quest to crack NEET 2020, you might have come across many books which claim to provide the best information. Students often rely on their peer

123 followers

A constructor is a block, called when an object is created. When the constructor is called memory of an object is allocated. The basic meaning of the

Java Object oriented programmi
47 followers

NTA has announced Postponement of Joint Entrance Examination (Main) April-2020. National Testing Agency DG Vineet Joshi issued a notice to reschedule

142 followers

GATE is an exam that consists of three sections namely Engineering Mathematics, Technical Subject and General Aptitude. The weightage of each of these

17 followers






















 Copy Link
Copy Link






